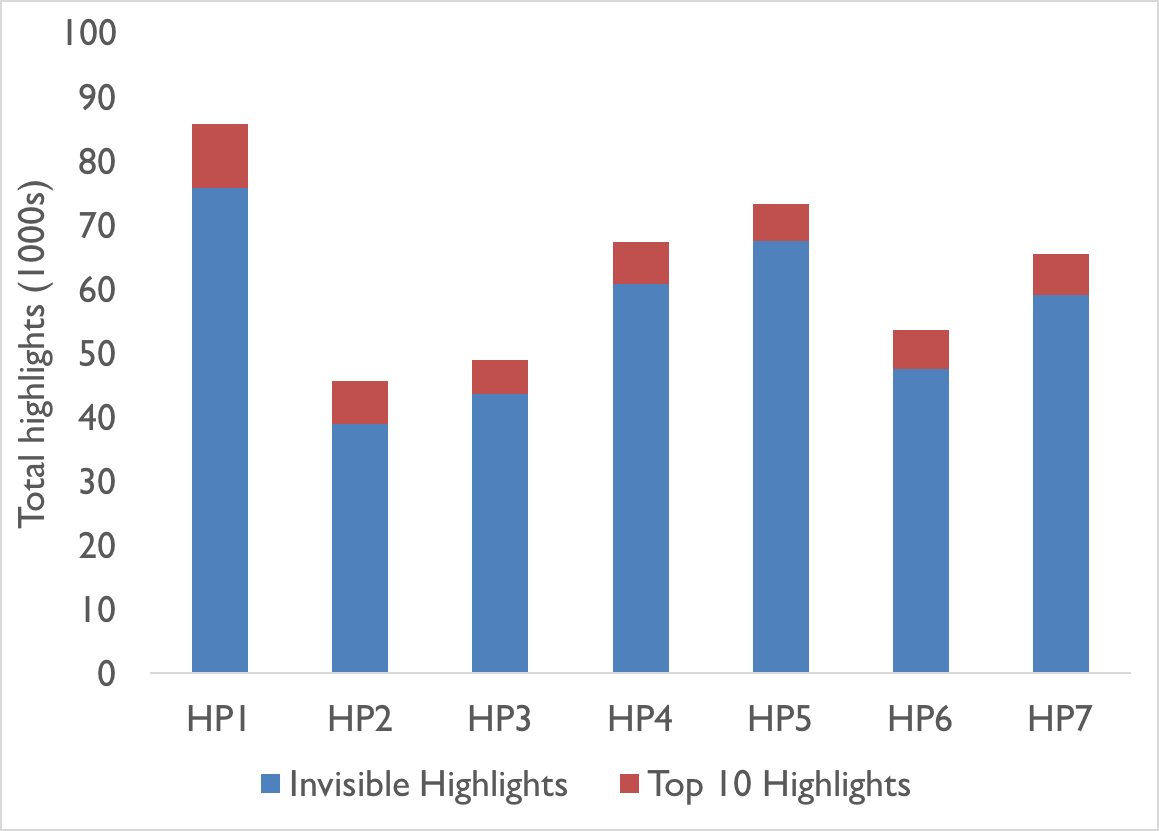
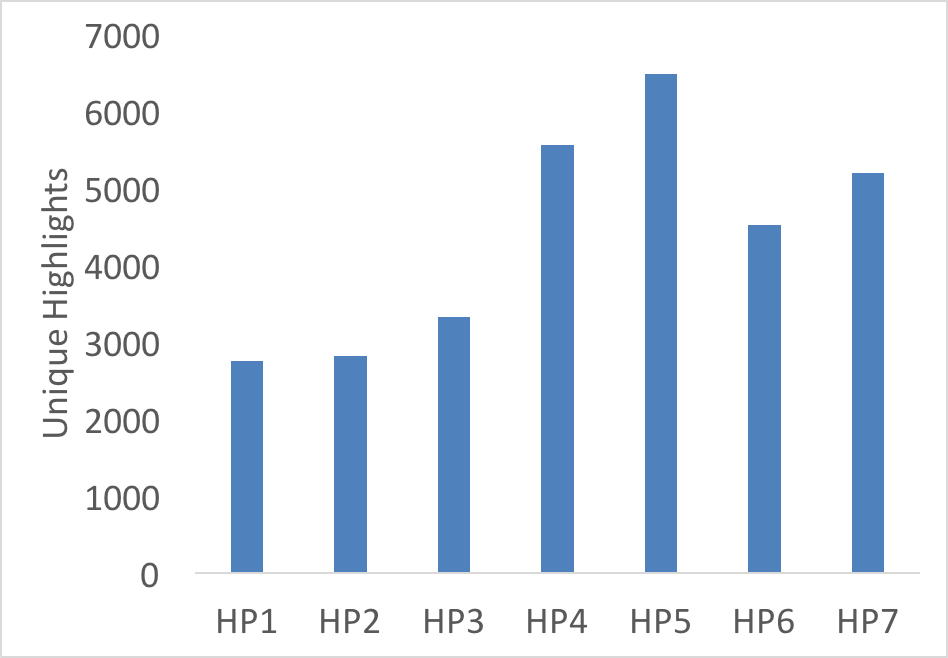
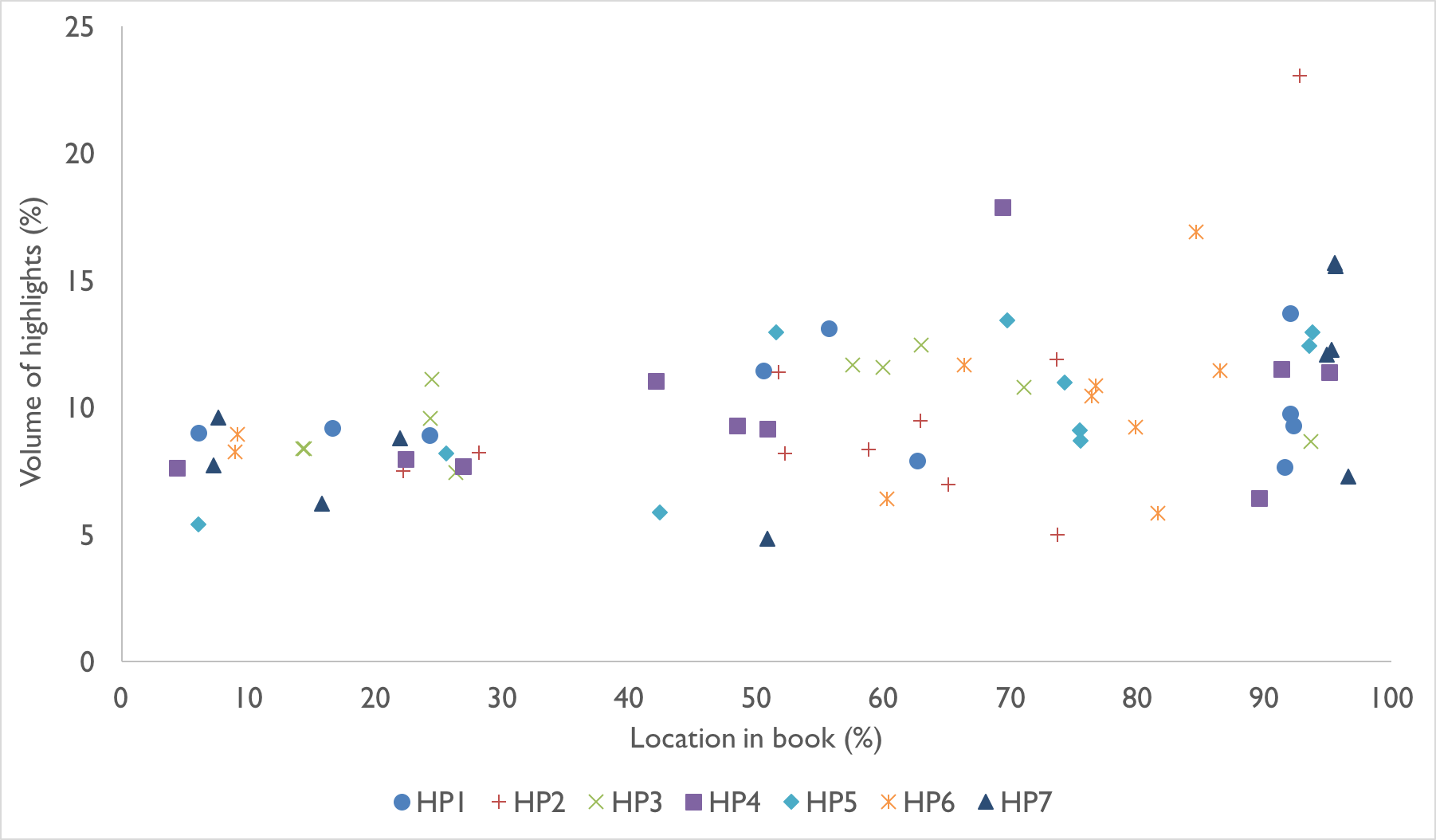
One of the problems with studying digital texts is coming up with a bibliographic description that captures enough information for others to identify (and often replicate the conditions) of the object. Unsurprisingly, ebooks have thrown up some interesting challenges for budding digital bibliographers.
Alan Galey has explored this issue across formats in The Enkindling Reciter. From this analysis, it is clear that the format of the ebook is important to record. For example, when talking about Walter Isaacson’s biography of Steve Jobs, the bibliographic record should indicate that the text was the ‘[Kindle edition]’ or ‘[EPUB]’. This is becoming standard practice in several venues, but is this sufficient to identify an edition?
Unfortunately, ebooks are likely to automatically update. Luckily, Amazon have several ways of identifying versions of a text:
- the Amazon Standardized Identifier Number (ASIN), the 10-character string which identifies each record in Amazon’s catalogue, which can vary between separate editions of the same ebook. For Walter Isaacson’s biography of Steve Jobs, the Little, Brown Book edition is B005J3IEZQ, while the Simon & Schuster is B004W2UBYW. This is not the case of a same book reskinned for different markets, as the Simon & Schuster file is eight times larger than the Little, Brown edition, which I will discuss here.
- The APNX file (used to generate page numbers) contains a ‘fileRevisionId’ (1378512022867) and ‘acr’, an identifier for a palm database (often a lengthy string, such as ‘CR!EBPXHWBERS4VV2GK50GFF58D17NS’). These values, while not infallible, can be used to match similar files.
Even this information is not sufficient for an accurate bibliographic description, since as I have argued elsewhere, the ebook must be considered as platform of at least four different layers: hardware, software, format and content. Without mapping all of these elements, it is impossible to accurately describe an ebook.
Just five words from Isaacson’s biography (“KOBUN CHINO. A Sōtō Zen…”) are sufficient to demonstrate why we need to pay closer attention to more than just the format of an ebook.
In the paperback edition of the text, the text is formatted with small caps and macrons on both the ‘o’s in Sōtō:
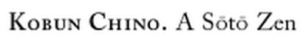
Walter Isaacson (2013) Steve Jobs. New York: Simon & Schuster, xiii.
The second generation Kindle renders this in a slightly different manner:
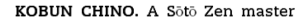
Kindle 2
This in turn is slightly different from the Kindle for Android, iPad, Mac & Cloud Reader edition:

Android 4.4.2 (Sony Xperia D2005 | Kindle for Android 4.13.0.203)

iOS 8.4 (iPad MD522B/A | Kindle for iPad 4.10)

Mac OS X 10.10.4 (Kindle for Mac 1.11.2 [40670])

Kindle Cloud Reader (Chrome 44.0.2403.125 | Mac OS X 10.10.4)
Variation in font and reading preferences aside, there are clear differences between versions that are of interest for the descriptive bibliographer. There are two major differences I want to highlight:
- Sōtō doesn’t look right in any of the Kindle edition.
- Kobun Chino’s name appears in small caps in the original print version, but not all Kindle platforms replicate this.
The first is a clear limitation of the Kindle platform and its design. Rather than using the rich and varied palette of a Unicode standard such as UTF-8 (allowing users to include a wide range of alphabets, and more importantly, emoji!), Amazon chose the much more restrictive Latin-1 encoding, which includes a range of diacritics and punctuation common to Latinate alphabets but not a lot else.
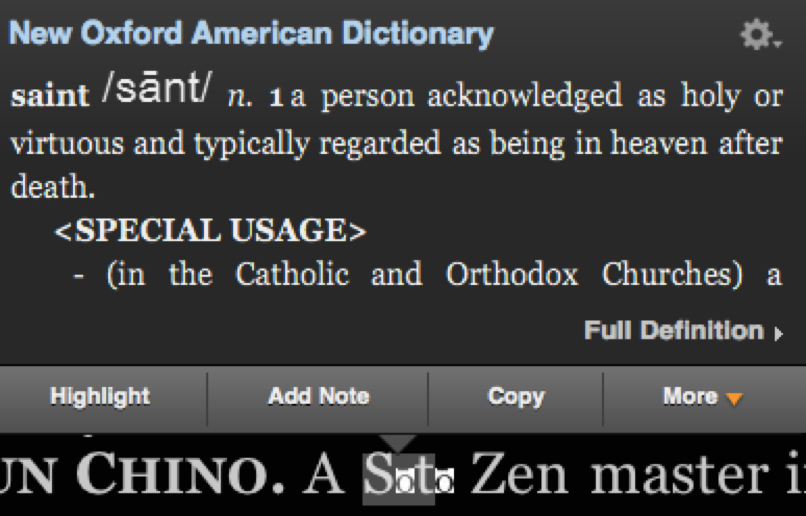
Unfortunately, this did not include the ‘o’ with macron, which just so happens to appear twice in a single word. Luckily, rather than simply removing the macrons, the producers have used a work round by including an image of the character. Unfortuantely, the image does not properly scale with the text and it only works with black text on a white background.
This has a couple of consequences for the ebook itself too, since it makes it impossible to search for ‘Sōtō’, as the text is either rendered into two single character words, or worse, turned into ‘St’. Not only does this make the word difficult to search for, but it also effects the quality of the Kindle’s text-to-speech facilities.
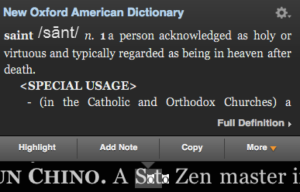
Sōtō rendered as “saint”
While the first bibliographic glitch was readily visible, the second would be difficult to spot without comparing different versions of the same edition. Formatting standards such as HTML, which ebooks use as their basic logic, are not hard laws, but recommendations for how to display text which can vary between different interpreters. Small caps is one of those features which is not universally supported by different instances of the Kindle application.
This may appear to be a minor aesthetic variation, but once again, it has an effect on the functionality of the ebook. Due to the variation in parsing the ‘small caps’ formatting tag, different versions of the Kindle software do not agree on whether the start of the ‘small caps’ formatting represents the start of a new word.
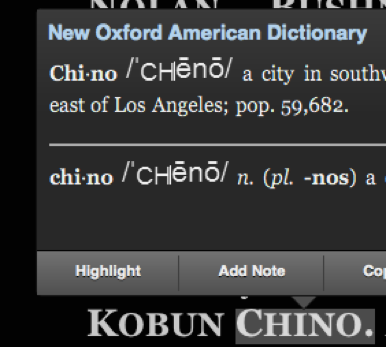
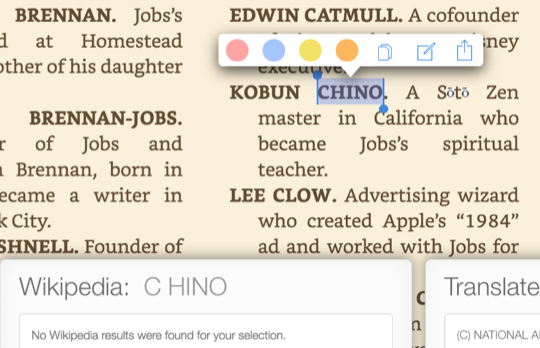
For example, Kobun Chino’s second name is rendered as ‘C hino’ on the iPad version, but remains ‘Chino’ on the Kindle for Mac version. This is a problem for readers who try to look up the name through the dictionary, Wikipedia or X-Ray, as the surname may be rendered as two separate words. Again, the text-to-speech functions of the Kindle stumble on this split word too, rendering some of the accessibility functions difficult to navigate.
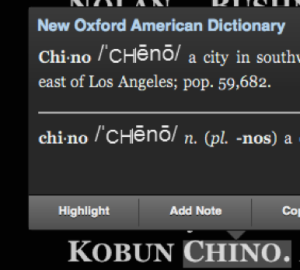
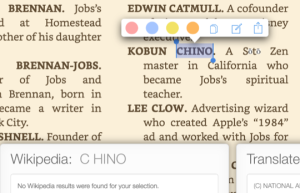
CHINO VS. C HINO
It is clear that identifying the brand and associated file format alone will not suffice, and even the file format may not be enough due to variation among platforms. Hardware and software configurations make a real difference in the version and behavior of the file. Since Amazon’s file formats (AWZ, PRC, KF8 and so forth) are not openly documented, so it is insufficient to look at the source code, noting the software and OS may be a necessary step in ensuring the replicability and accurate documentation of Kindle ebooks. Even this may not be enough to stave off the constantly updating Kindle infrastructure, but at least it’s a start towards documenting a specific moment in time.