Abstract: Amazon’s dominance of the ebook trade since 2007 can be credited to their erasure of evidence about the historical development of ebooks prior to the launch of the Kindle. This activity included removing catalogue records for their ‘Ebook and E-Doc’ store, a strategy Amazon repeated with the removal of old public domain Kindle titles in 2014. Early ebook experiments prior to the Kindle were not financially lucrative but provided the foundation for the platform’s future success. In this presentation, I will explore the challenges of analysing contemporary digital publishing due to the shifting landscape prior to the Kindle’s entry to the market. I will use a case study of Microsoft LIT format (discontinued in 2012) and MSLit.com, Microsoft’s dedicated catalogue of ebook titles to demonstrate the importance of the catalogue website for contemporary book historical research.
The preservation of the original ebooks is an optimistic ideal for platforms that have shut down and are therefore only available for consumers who have kept backups of files from at least half a decade ago. As a consequence, catalogues are vital evidence of what titles were available for sale. The reconstruction and preservation of these corporate catalogue records, only partially available through the Internet Archive’s Wayback Machine. The preservation of these metadata sources allows for a more comprehensive understanding of the history of the ebook and the flow of content from platforms as they fall in and out of fashion. In this paper, I present some initial findings from reconstructing this catalogue and highlight the importance of archiving contemporary ebook catalogues to preserve important evidence of early twenty-first century publishing practices.
PRESENTATION: Strategies for reconstructing the pre-history of the ebook through catalogue archives
September 15th, 2017 § 0 comments § permalink
Social Reading of Harry Potter on the Kindle (from a distance)
October 20th, 2015 § 0 comments § permalink
I’ve been seriously working on research for my history of the Kindle for a couple of years now and I’m still figuring out how to capture the impact of the Kindle on the scale of both the publishing/technology industry and the individual reader.
This tension is clearest when looking at the available data on reading and the shared highlights. There are a large number of individuals making personal choices behind the 500,000 shared highlights of a single edition of Wuthering Heights. If we scale this to over 4 million ebooks and 40 million Kindle users, it becomes extremely difficult to focus on both the local and global trends (and doubly so when access to the data is obsfucated and entirely unavailable): What counts as an appropriate sample? To what degree can individual highlights link to the mass of activity? How much data can I even get hold of?
While I ponder these questions, there’s still the problem of method. In order to figure this out, here’s a pilot study of the Harry Potter series as a complete unit that is manageable yet has received a fair amount of attention.
On the global level, shared highlights might not be able to tell us much about readership because an unknown number of readers choose not to highlight or share their efforts. The benefit of using Harry Potter, however, comes from the fact it is possible to gauge popularity across the series.
In recent versions of the Kindle software, a helpful pop-up box appears “About This Book” when opening a title for the first time. Luckily, this pop-up contains the total number of shared highlights and how many unique sections of the title have been highlighted. (These may not necessarily be up-to-date, but all the data here comes from 20 October 2015)
The data from the Harry Potter series reveals some interesting patterns. Figure 1 shows the total volume of shared highlights for each title, while figure 2 looks at the number of unique highlights per title. The most striking part of figure 1 is that the visible highlights (the top 10 most shared highlights) barely represent 10% of all shared highlights for any individual title.
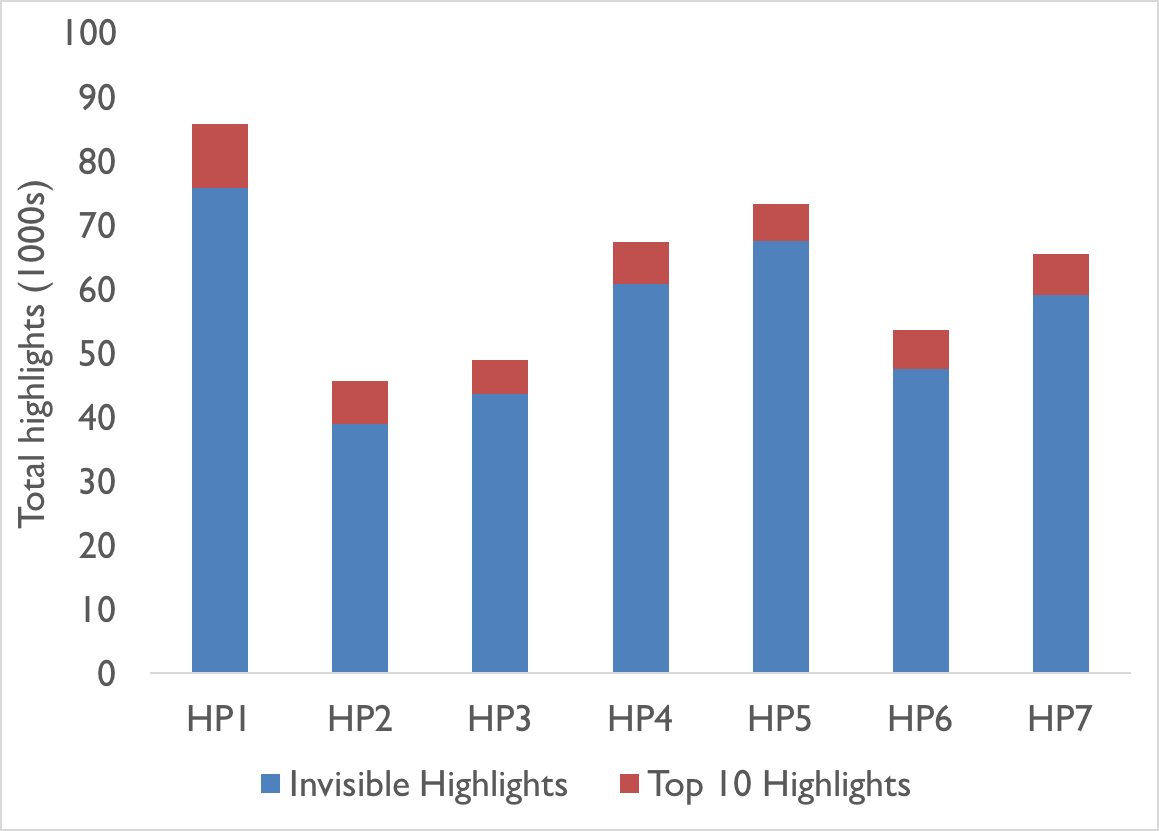
Figure 1. Total highlights for each Harry Potter title and the visible top 10 highlights (click for full size)
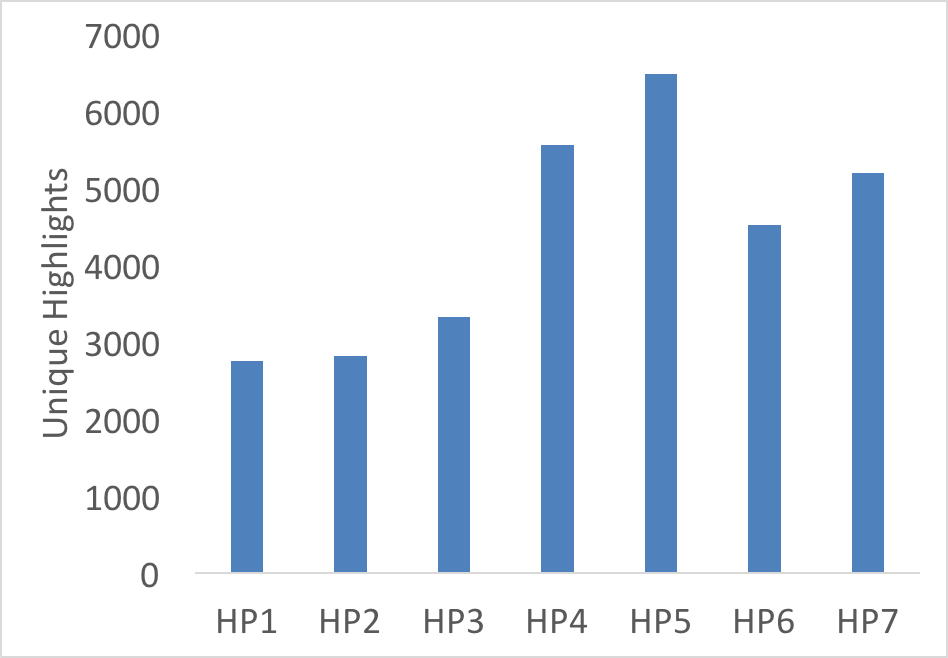
Figure 2. Unique highlights for each Harry Potter title (click for full size)
While the two graphs appear to show that the popularity of the series drops at the end and plummets after the first novel only to be pick up towards the middle, there is a far simpler explanation: the longer books receive more highlights as there is more text to highlight.
The only notable exception is Harry Potter and the Philosopher’s Stone, where more readers are focusing on particular passages. The large increase in total highlights without a similar increase in unique highlights likely indicates that more people are reading the first book than the rest of the series, or at the very least, they lose enthusiasm after the first book.
The second macroscopic view we can get from the Popular Highlights is the location of the shared highlights. Jordan Ellenberg has coined the Piketty Index as a way of using popular highlight locations to see how far through a book a reader got before quitting. From the evidence I’m gathering, it looks like the top 10 shared highlights are more likely to appear at the beginning of a book than the end, but what about the Harry Potter series?
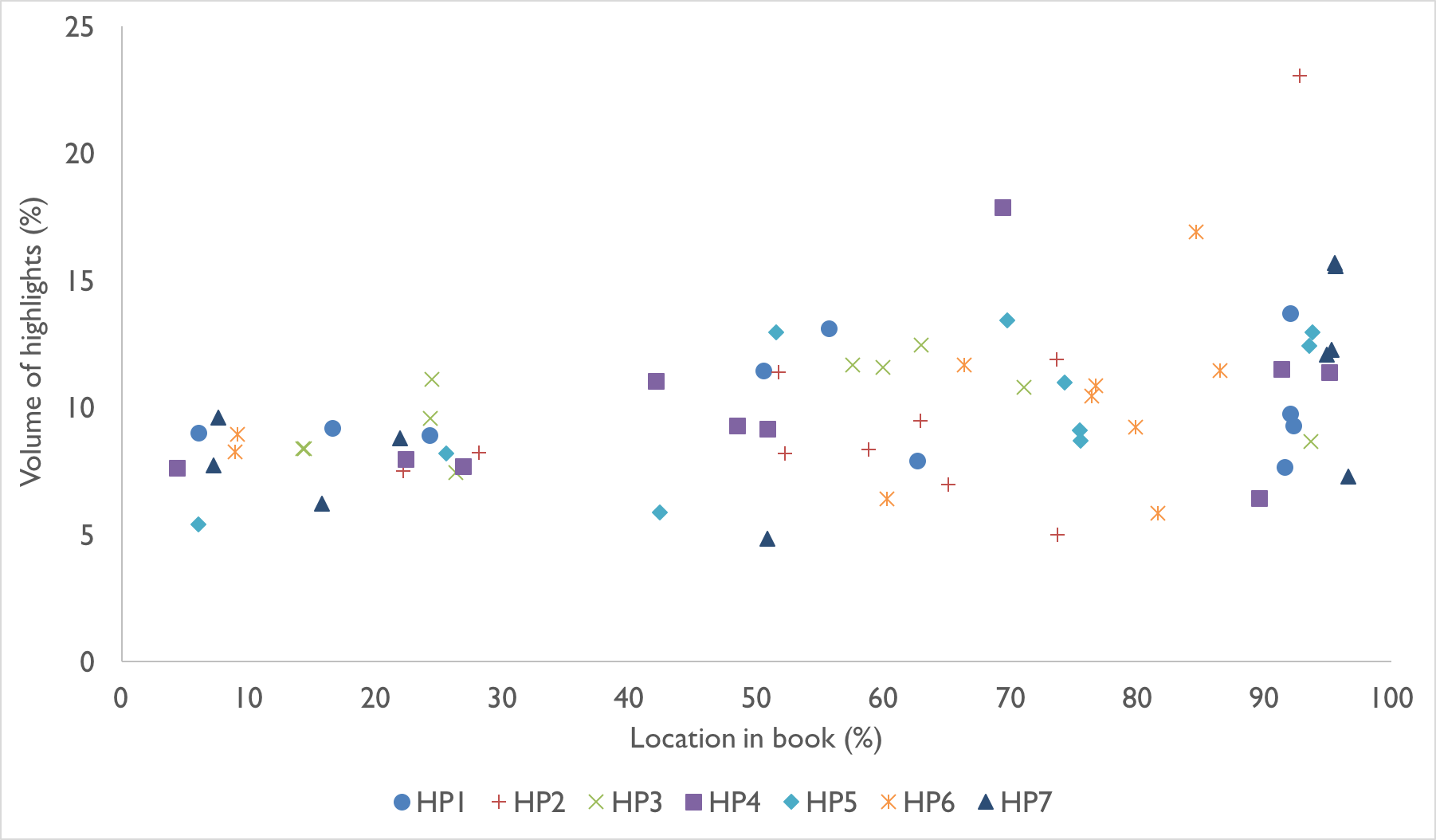
Figure 3. Top 10 Shared Highlights for each Harry Potter title (click image for full size)
As a series, readers are more likely to highlight passages at the end of the book than the beginning. Not only does this suggest that readers are likely to finish the books, but through looking at the content of the highlights from the end of the book, it is clear that some of the most popular parts of the titles are Dumbledore’s speeches to Harry and the denouement of the narrative. Given the make-up of Rowling’s series and the slow start of most of the books, this inversion makes sense.
And that’s about as much as you can deduce from looking at the global level as far as I can tell. Once I’ve dug into the more traditional annotations and highlights of individual readers, I’ll compare the results with the broad patterns identified here.
Amazon is 20 years old – and far from bad news for publishers
July 16th, 2015 § 0 comments § permalink
I was asked to write about the importance of Amazon for publishers for the company’s 20th anniversary in The Conversation. It was originally published here: theconversation.com/amazon-is-20-years-old-and-far-from-bad-news-for-publishers-43863
It has now been 20 years since Amazon sold its first book: the titillating-sounding Fluid Concepts and Creative Analogies, by Douglas Hofstadter. Since then publishers have often expressed concern over Amazon. Recent public spates with Hachette and Penguin Random House have heightened the public’s awareness of this fraught relationship.
It has been presented as a David and Goliath battle. This is despite the underdogs’ status as the largest publishing houses in the world. As Amazon has become the primary destination for books online, it has been able to lower book prices through their influence over the book trade. Many have argued that this has reduced the book to “a thing of minimal value”.
Despite this pervasive narrative of the evil overlord milking its underlings for all their worth, Amazon has actually offered some positive changes in the publishing industry over the last 20 years. Most notably, the website has increased the visibility of books as a form of entertainment in a competitive media environment. This is an achievement that should not be diminished in our increasingly digital world.
Democratising data
In Amazon’s early years, Jeff Bezos, the company’s CEO, was keen to avoid stocking books. Instead, he wanted to work as a go-between for customers and wholesalers. Instead of building costly warehouses, Amazon would instead buy books as customers ordered them. This would pass the savings on to the customers. (It wasn’t long, however, until Amazon started building large warehouses to ensure faster delivery times.)
This promise of a large selection of books required a large database of available books for customers to search. Prior to Amazon’s launch, this data was available to those who needed it from Bowker’s Books in Print, an expensive data source run by the people who controlled the International Standardised Book Number (ISBN) standard in the USA.
ISBN was the principle way in which people discovered books, and Bowker controlled this by documenting the availability of published and forthcoming titles. This made them one of the most powerful companies in the publishing industry and also created a division between traditional and self-published books.
Bowker allowed third parties to re-use their information, so Amazon linked this data to their website. Users could now see any book Bowker reported as available. This led to Amazon’s boasts that they had the largest bookstore in the world, despite their lack of inventory in their early years. But many other book retailers had exactly the same potential inventory through access to the same suppliers and Bowker’s Books in Print.
Amazon’s decision to open up the data in Bowker’s Books in Print to customers democratised the ability to discover of books that had previously been locked in to the sales system of physical book stores. And as Amazon’s reputation improved, they soon collected more data than Bowker.
For the first time, users could access data about what publishers had recently released and basic information about forthcoming titles. Even if customers did not buy books from Amazon, they could still access the information. This change benefited publishers as readers who can quickly find information about new books are more likely to buy new books.
World domination?
As Amazon expanded beyond books, ISBN was no longer the most useful form for recalling information about items they sold. So the company came up with a new version: Amazon Standardized Identifier Numbers (ASINs), Amazon’s equivalent of ISBNs. This allowed customers to shop for books, toys and electronics in one place.
The ASIN is central to any Amazon catalogue record and with Amazon’s expansion into selling eBooks and second hand books, it connects various editions of books. ASINs are the glue that connect eBooks on the Kindle to shared highlights, associated reviews, and second hand print copies on sale. Publishers, and their supporters, can use ASINs as a way of directing customers to relevant titles in new ways.
Will Cookson’s Bookindy is an example of this. The mobile app allows readers to find out if a particular book is available for sale cheaper than Amazon in an independent bookstore nearby. So Amazon’s advantage of being the largest source of book-related information is transformed into a way to build the local economy.
ASINs are primarily useful for finding and purchasing books from within the Amazon bookstore, but this is changing. For example, many self-published eBooks don’t have ISBNs, so Amazon’s data structure can be used to discover current trends in the publishing industry. Amazon’s data allows publishers to track the popularity of books in all forms and shape their future catalogues based on their findings.
While ISBNs will remain the standard for print books, ASIN and Amazon’s large amount of data clearly benefits publishers through increasing their visibility. Amazon have forever altered bookselling and the publishing industry, but this does not mean that its large database cannot be an invaluable resource for publishers who wish to direct customers to new books outside of Amazon.
The strange orthography of ebooks
February 9th, 2015 § Comments Off on The strange orthography of ebooks § permalink
While the ebook has become a familiar concept since 2007 and the launch of the Kindle, there appears to be little consensus over how exactly to spell it. There appear to be three main contenders: e-book, ebook, and eBook.
Unfortunately, it is difficult to trace usage of small orthographic differences to see the popularity of each over time, but there are clear comparisons with the term ’email,’ which started off with the hyphen (e-mail) but is now normally simply spelled email as it has become the standard form of communication over the postal system. In early discussions around ebooks, a hyphen similarly marked the emergent form as alien and distinct from its printed counterpart. Perhaps over time we will drop the hyphen and this ellipsis will demonstrate how the ebook has become embedded within contemporary culture, as it is possible to trace with email.
But this leaves the question of the third orthographic variation, ‘eBook.’ While this may look like a riff on Apple’s branding for the iPod and associated devices, it’s history goes back much further to the first generation of commercial ebook device, and the Rocket eBook in particular. A couple of other devices borrowed the orthography, and it appears to have caught on beyond the brand. Interesting, since the ebook revival in 2006, this orthographic convention has not been widely copied, perhaps due to the dominance of Apple with that kind of orthography. Given its awkwardness, particularly when using the word at the beginning of a sentence, perhaps it should be used only with reference to these historic devices.
Twitterbots: Reading Automata
June 9th, 2014 § Comments Off on Twitterbots: Reading Automata § permalink
One of Twitter’s unique selling points as a social network is its unerring focus on text. Even posting a picture or video independently generates a textual anchor for the media in the form of an URL. As a textual media, Twitter’s primary currency is reading. The politics of reading, and more typically, not reading, characterizes a user’s relationship with their audience of followers and beyond.
It turns out that some of Twitter’s most voracious readers are not human at all, but rather the range of artisan bots that have emerged in the last couple of years. While they vary in type dramatically (Tully Hansen’s taxonomy covers this territory well), at the most fundamental level these bots are reading machines. On a basic level, the tweets emerge from the bots reading, and enacting, their source algorithms, but their literacy extends beyond that. These bots do not generate material out of nothing but rather than read a variety of sources—Twitter searches, the dictionary, novels, ROM texts, headlines, and other assorted materials—and present their readings as new writings.
This sleight of hand, based upon the process of reading to write, is reminiscent of automata that have intrigued countless historical audiences. Through use of clockwork and other mechanisms, automata maintain an illusion of autonomy. Once the underlying mechanics have been figured out, the automata become either trivial or joyful for appreciating the underlying mechanics. Twitterbots garner similar reactions once the processes have been understood, although many make use of dynamic and timely reading sources to ensure proceedings do not become stale. Nonetheless, Adam Parrish’s @everyword, a project that undertook its name in alphabetic order, is probably the most popular bot, despite its stable reading material and its relative predictability ending (that was eventually subverted due to collating words starting with é after z).
@horse_ebooks, the most contentious, and previously beloved, of all Twitterbots has a special place in this analogy: the machine that was disappointingly all too human in the end. The grand reveal that the account which generated bizarrely poetic and uncommercial spam was in fact a human performance mirrors the trajectory of a human-run automata affectionately known as the mechanical turk (picked as a name for Amazon’s crowdsourcing service due to its namesake’s “artificial artificial intelligence”). The Turk appeared to be a brilliantly gifted automatic chess-player that was actually entirely controlled by a human hidden in a secret compartment behind the false clockwork. The performance that fueled @horse_ebooks’s final years equally represented a kind of reverse Turing Test, whereby a human attempted to appropriate the linguistic tics of a bot.
These reading automata become much more interesting when considering the ways in which they challenge our notions of reading. Take, for example, Mark Sample’s Station 51000 (@_LostBuoy_), which plays with the tensions of reading on various levels currently being teased out in humanities research. The bot mixes a reading of sections of Moby Dick with live data from the unmoored buoy classified as station 51000. Despite the specificity of location, the buoy still transmits a range of maritime data. The mash-up of a single, fixed, canonical work of literature with an erratic stream of nautical data goes beyond a comical clash of high culture, low culture and data—it reflects upon digital methodologies of reading that have emerged in recent decades including the use of “big data.” Of course, I’m not the first one to notice this, and the trend in Twitterbots more generally:
a twitter bot is a pretty good way to read a text that would otherwise be interpreted as “not meant to be read”
— aparrish (@aparrish) February 20, 2014
As automata, it is not up to these bots to make aesthetic decisions, as evidenced by Station 51000‘s mixture of the literary and real-time feed. Instead they can be used to push the limits of what reading means, and occasionally make us smile or laugh.
Call for Papers: New Sites of Worship [SHARP 2014]
October 22nd, 2013 § Comments Off on Call for Papers: New Sites of Worship [SHARP 2014] § permalink
Next year’s SHARP conference in Antwerp (17-21 September 2014) has the central theme of ‘Religions of the Book’. I would be interested in submitting a proposal for a session on ‘New Sites of Worship’ and invite anyone interested in this theme to join this session.
The rise of new social networks and websites both general (e.g. Facebook, Twitter, Tumblr) and those geared towards reading (e.g. Goodreads, Shelfari, LibraryThing) have led to ‘new sites of worship’ for fandom of literary authors. Users have populated these sites to discuss their favourite authors and books. Occasionally this discourse has become out-of-control and fandom has become fanatical and discussion of the literary turns into worship.
The proposed session will explore the traces of rabid fandom online including but limited to role-play, interaction with authors, obsession and misuses of social media. Please send a short abstract (400 words) to Simon Rowberry (s.rowberry.13@unimail.winchester.ac.uk) by Thursday 28 November if you want to participate in this session.
The Public and Private Nabokov
October 18th, 2013 § Comments Off on The Public and Private Nabokov § permalink
It is well known that Nabokov projected a persona in his rare public statements and interviews. He used such occasions to stamp his authority on his texts and to preserve the myth of a solitary genius who was not fond of many other authors. It is unsurprising that his correspondence reveals a different, more personable character. Make no mistake, Nabokov-as-public-figure appears in some letters to publishers and authors as he denounces second-rate authors and those who introduce errors into his works!
One of the many examples of this discrepancy can be seen in Nabokov’s mentions of the typewriter in his correspondence and published interviews. Nabokov’s composition method after 1941 relied on index cards and pencils, a method he had transferred from his research into butterflies. When the time came to type up these index cards, he left the typing to his wife, Véra. Although this offers no direct evidence that Vladimir himself could not type, in personal correspondence to James Laughlin, an early American publisher of Nabokov’s novels, in November 1942, Nabokov admitted parenthetically that “I cannot type.” (Selected Letters, 43)
Three years later, however, he included a holograph to a typed letter to Katharine White: “This is the first letter I have typed out myself in my life. Took me 28 minutes but came out beautifully.” (SL, 54) Here we can see an apprentice’s pride and an appreciation of the aesthetic value of typing, especially through the struggle. This moment of glory is in stark contrast to Nabokov’s public pronouncement years later (1963) in a Playboy interview to Alvin Toffler: “Yes I never learned to type.” (Strong Opinions, 29). Undoubtedly after his initial struggle, he did not take over all his typing duties, but under such a public statement lies a much more complex private engagement with the technology he dismisses.
Do we need an E-lit Short Title Catalogue?
September 3rd, 2013 § Comments Off on Do we need an E-lit Short Title Catalogue? § permalink
I’ve spent the day successfully viewing the copy of William Gibson, Dennis Ashbaugh and Kevin Begos Jr.’s Agrippa: book of the dead at the National Art Library (once I’ve gathered my thoughts and reorganized my notes – I’ll write up my findings regarding the differences between this and other editions of the text) and being unsuccessful in an attempt to see Mark Hansen and Ben Rubin’s Listening Post currently installed next door at the Science Museum. These are two works of hybrid physical-digital literature that can’t easily be replicated and distributed widely among the community, but equally are incredible works that require physical interaction in order to fully appreciate them. Certainly, Agrippa was a completely different physical experience than I had imagined from any description I had read.
Along with other important works of digital literature, there are very few, if more than one, functional copies of these two artefacts. Preservation has been a pressing need within the community as the wealth of recent literature would suggest. In recent years there have been a promising number of acquisitions of important digital literature author’s papers in libraries and a number of laboratories doing important work such as the Media Archaeology Lab, UCSC’s large collection of Japanese videogames, MIT’s Trope Tank, etc (As an aside, I don’t know if there is any such lab in the UK yet?). The currently on-going NEH Office of Digital Humanities project, “Pathfinders” has been instrumental in the promoting preservation through documentary and “Let’s Play” practice. This is useful work for the institutionalization of digital literature but access remains an issue.
If some of these works are still executable in their original form, or preserved in some other form if they take are very physical (e.g. Where can I access works built to run with CAVE?), how do we find out where these places are? Catalogues of digital works are being built: ELMCIP, Electronic Literature Directory, I ♥ E-Poetry, and so forth, but a common finding aid for where to travel to when you actually want to interact with these works is still missing.
A useful analogy for what might solve this problem can be found in one of the great undertakings of bibliographers in the last 150 years: the Short Title Catalogue (STC). The STC was a monumental undertaking to document the existing copies of books printed between 1475 and 1640 in the British Isles and notes the libraries that held the titles. Rather than noting all books that could have existed, it focused instead on those that survived. This allowed researchers to find copies of these rare materials. Surely many of digital incunabula deserve similar treatment?
Now, the short title aspect of the work is no longer important as digital bibliographies allow for longer records, and the STC itself is now online with much more metadata than the crammed references of the printed original. Equally, the records of locations has changed since the revised edition, and with issues such as the Senate House Library’s proposed sales of their Shakespeare Folios, the catalogue remains in flux and libraries may no longer have the same holdings. The STC instead offers a starting point.
The finding aid aspect of the STC would be of great use for scholars interested in the material aspects of digital literature. If we had a centralized database offering the locations and any system requirements based upon the limitations, this could aid access to the original artefacts and enrich our understanding of early digital literature. Setting up such a database would be another step towards legitimizing the form as it would once more demonstrate the importance of the material form as something worth traveling for, rather than relying on the description of those earlier scholars lucky enough to interact with some of the more elusive and ephemeral works.
Error, Failure and Nabotov
August 26th, 2013 § Comments Off on Error, Failure and Nabotov § permalink
I’ve recently created my first Twitterbot, Vladimir Nabotov, by appropriating the code from Zach Whalen’s brilliant Pelafina Lièvre. The bot itself is fairly derivative and works on the principle of Markov chains, but the source material is esoteric enough to deserve further comment.
The bot draws its source material from bootleg versions of Nabokov’s works available online with all the errors, typographical quirks and other peculiarities. Using Nabokov as source material is also problematized by Nabokov’s frequent code-switching between English, Russian and French.
Automatically generating tweets can often lead to failure, as the source might not be an interesting section of the text or the bot might post something offensive. Nabotov embraces this failure with the “dirty” source material. This can lead to some familiar motifs being recast in new forms:
Lo-less when I strolled back.
— Vladimir Nabotov (@VVNabokov) August 26, 2013
Equally, there can be some interesting results with non-English languages, such as this snippet of Zembla:
Ufgut, ufgut, velkam ut Semblerland! — Vladimir Nabotov (@VVNabokov) August 24, 2013
These results would be desirable in a usual twitterbot, but the missteps reveal problems with the texts readers are most likely to encounter if they are unwilling to purchase a copy of a carefully produced book. This can take the form of weird glyphs, errant punctuation (Nabokov loves his parentheses!) and conjoined words:
Ma belle-mère avale son râtelier. Grishkin, an overtly subtle yam extolling the Roman faith. — Vladimir Nabotov (@VVNabokov) August 24, 2013
CreamThis is not quite exact. Serious?… No, I hope not.
— Vladimir Nabotov (@VVNabokov) August 24, 2013
Failure is often banded around as an important aspect of the digital humanities, and twitterbots certainly allow us to understand the potential failure (and harm) of generative writing, but equally, this failure can be channeled to examine other types of failure too.
More on “Lolita is Famous, Not I”
August 18th, 2013 § Comments Off on More on “Lolita is Famous, Not I” § permalink
Inspired by Juan Martinez’s excellent visualization comparing mentions of Lolita to Nabokov in the Google Books corpus (and the 55th anniversairy of Lolita‘s publication in America today!), I thought I would delve a little deeper into the Google Books n-gram data available and test the claims using the raw data (which admittedly is very rough and contains a lot of duplicates, but others a rough estimate of volumes current digitized by Google).
Looking at raw 2-grams (that is, all instances of “Lolita” and “Nabokov” with one word after it referenced in the most up to date data sets available from Google), there are two figures available for analysis: the number of times a word is mentioned in the complete corpus, and the volume of texts that reference the word at least once.
The online viewer does not distinguish between the two categories and is case-sensitive, so the raw data gives us more data to play with.
There is a clear difference between the total references and the numbers of books using the words, as one book may repeatedly mention Nabokov but never Lolita, popularity should be mapped by the number of texts using the word, rather than the total references. Such a graph still shows that Nabokov is more popular for most years other than the publication of Lolita, as Juan noted, and the period from 1966-1969 for some reason.
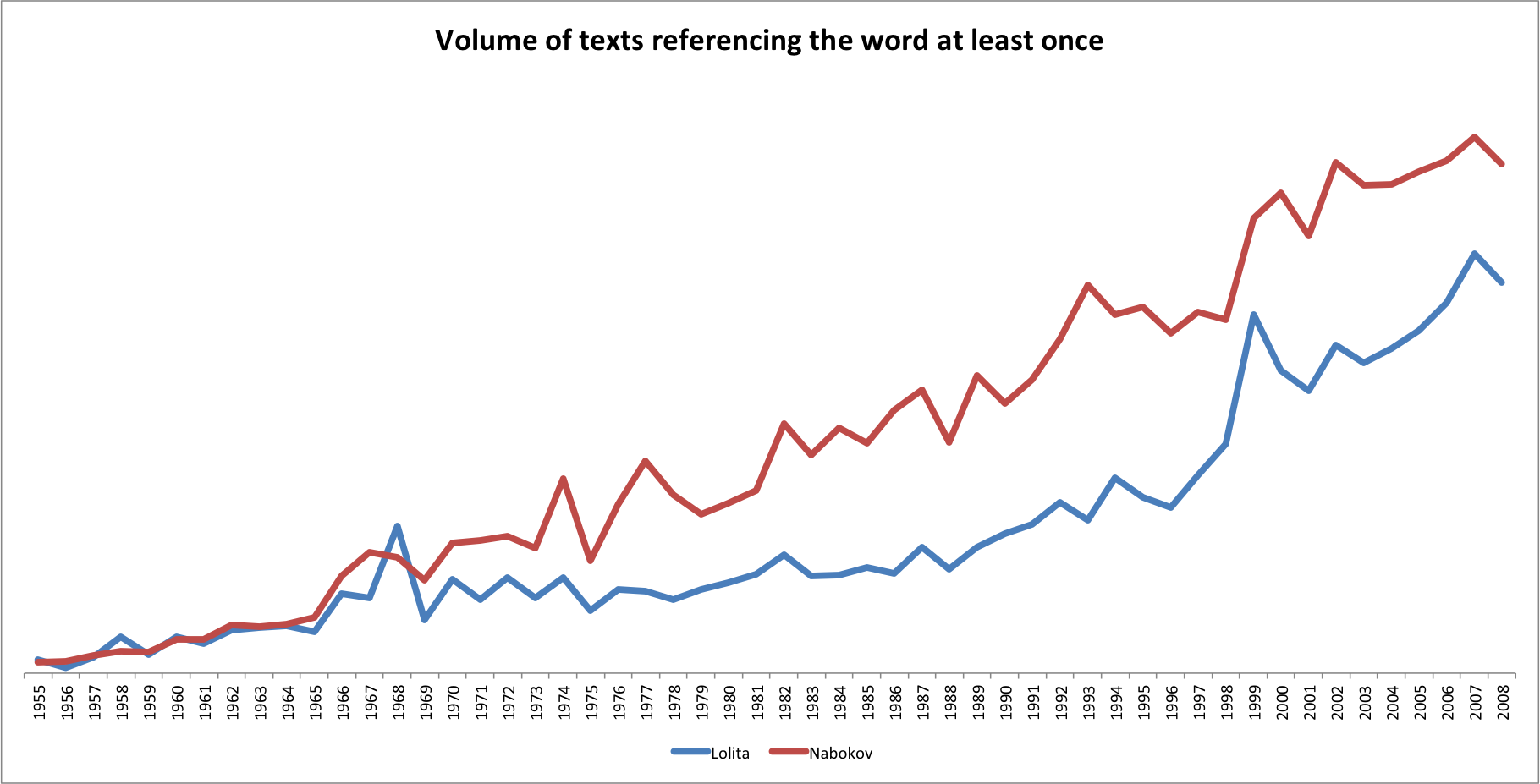
Click for large
The average number of references per book further asserts Nabokov’s enduring popularity. Since Nabokov is mentioned on average more times than Lolita, not only is he discussed by a broader range of texts, but they are engaging with him as a subject in a deeper manner than Lolita.
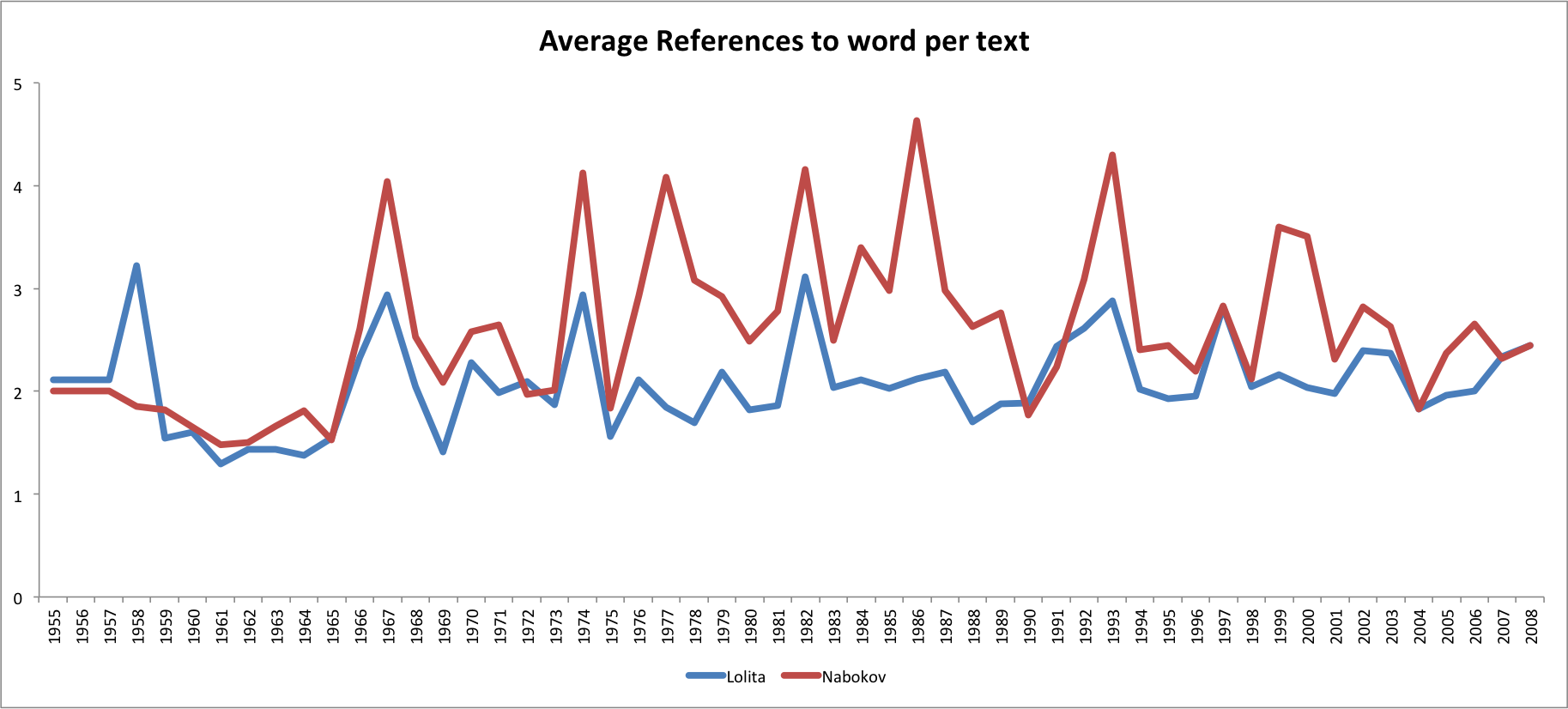
Click for large
There were also some interesting phrases that came out of the data, with their first data of use next to them:
- Lolita sunglasses (1976)
- Lolita complex (1959)
- Lolita Delores (1962)
- Nabokov Festival (1985)
- Nabokov studies (1967)
- Nabokov archive (1989)